How the ancient Greeks were better programmers than you
Regular software engineering trusts that a system, given the same input, will always give the same output. However, when you enter the payments world, anything can happen after you click on that “pay” button.
In this talk, I explore the parallels between Stoic philosophy and payments engineering. The Stoics understood that we cannot control external events—only our responses to them. This wisdom translates directly to building payment systems that must handle:
- Unpredictable PSP responses - Timeouts, partial failures, and inconsistent error codes
- Network unreliability - The fallacies of distributed computing hit hard in payments
- Asynchronous reconciliation - When “success” doesn’t mean the money actually moved
- Fraud and chargebacks - External actors actively working against your system
The key insight? Build systems that expect failure, not systems that assume success. Design for the chaos, and you’ll find peace in production.
View transcript (auto-generated)
Auto-generated YouTube captions, cleaned up: sentence case, punctuation, paragraph grouping, and known mis-recognitions fixed. A few
[?]markers indicate spots where the auto-caption was unclear. For the canonical version, watch the video.
Hello, welcome, and thanks for joining me. This presentation is called Payments Engineering and Stoicism. I want to talk about how they relate, and why the ancient Greeks were better programmers than you.
First of all, a bit of introduction about myself. I decided today to introduce myself by the books that I love.
The first one is Clean Code by Robert Martin. This is mainly because I was a professor in Uruguay, my home country, and I used to bash my students with it — but I actually love it, because it’s a collection of advice that is useful for everyone when you are programming.
Then Software Architecture in Practice is also another book that I loved from my university times, and it has helped me a lot in my work life.
And lately I’ve read Dark Matter Markets. This book is amazing regarding fraud and credit card payments online, and how that can be very challenging for all of us.
On the other side, I have three different books from three authors that lived more than 2,000 years ago, and they are still very current for the topic that I will be talking about.
So, first of all: why is stoicism — and what is it for those of you that don’t know it? First of all, stoicism is a way to live your life better. So, all of us are actually living our lives, thankfully — but stoicism is how we can live it better, and how we can be happier, which is a very difficult thing to find. It’s a good way to study and get to know yourself, and how to improve your life.
How did I come into studying stoicism? It’s very related to my career as a payments engineer, and you will be hearing about why I relate to them.
One of the most basic values that they share is the trichotomy of control. This actually comes from a different version: Epictetus had a dichotomy of control, and one of the authors of recent books about stoicism reframed this as a trichotomy.
Basically, this means that you have to be very aware of what is in your control in your life, what is not in your control, and what are the things that you can influence — kind of have control over them, but not a hundred percent. It means that you are the one who determines your reaction to a crisis and to anything that happens in your life. So you are in control of how you live your life and how you react to everything that others do to you, that your work does to you.
Well, in payments — how do providers, cards, users, etc. relate to you, and how do they affect your work life and also your personal life?
One of the most important quotes that I would like to share with you is: “Waste no more time arguing about what a good man should be. Be one.” That was shared by Marcus Aurelius, which I think is still pretty current for our times, and it’s very, very applicable to work as a payments engineer — because we are all the time saying how our code should be, how our providers should behave, how other developers should be working with us. But many times — and I feel guilty about that — many times we didn’t do everything that was under our control to at least improve the part that we can, and then show the example to everyone else, and survive in the process, let’s say.
So, as a payments engineer, I collected some questions that we get. Most of all, I wanted to differentiate it from a normal software engineer, which is how I started my career — and many people here are working as such.
What’s different about payments in general is that the software development life cycle traditionally means that we agree on a design after collecting the features that we want, and agreeing with the product and business people on how and what we want to build. Then we go in cascade, or iterations, or scrum, or whatever, and we arrive to a certain result that is measurable. If we did it correctly, it’s testable; and if it works correctly, the system that we designed, given the same input, should always give you the same output.
We are always proud as engineers, saying that the computer is never wrong — and who is wrong is the one who made it wrong.
So in payments, there are so many things that can go wrong, and so many teams and companies and processes involved, that it’s necessary to create even a different industry — or some industry inside software engineering. I’m going to be talking more deeply about that.
Many of the questions that we get as payments engineers are: “Why are you taking so much time, two months or more, for just calling an API endpoint that is /pay and sending a card and an amount? This payment integration is exactly the same as others that you have, so why are you taking so much time for it?”
“And if you’re having problems testing the integrations, why don’t you mock the responses?” This is actually a very common question from other software engineers, where we have the possibility to mock responses from other services or other modules.
Then, the infamous “it works in my machine, but when I went to production it didn’t work.” So another question that we receive all the time is: why?
The most important question that we get — and we should always have the answer for — is: where’s the money? At any moment in time we should know where the user’s money is, and we don’t always know. And that’s when I go back to my stoicism background. You need to know how to handle that stress and how to handle the pressure of a CEO not being able to pay, and you are the one who needs to know why. Or even worse: the CEO did pay, but we don’t know where the money is, because the provider didn’t receive it.
But yeah, everything is super complex, so you need to go back to: what can you control, and what can you do about it, and how can you prepare for it? Stoicism helped me a lot in my daily life.
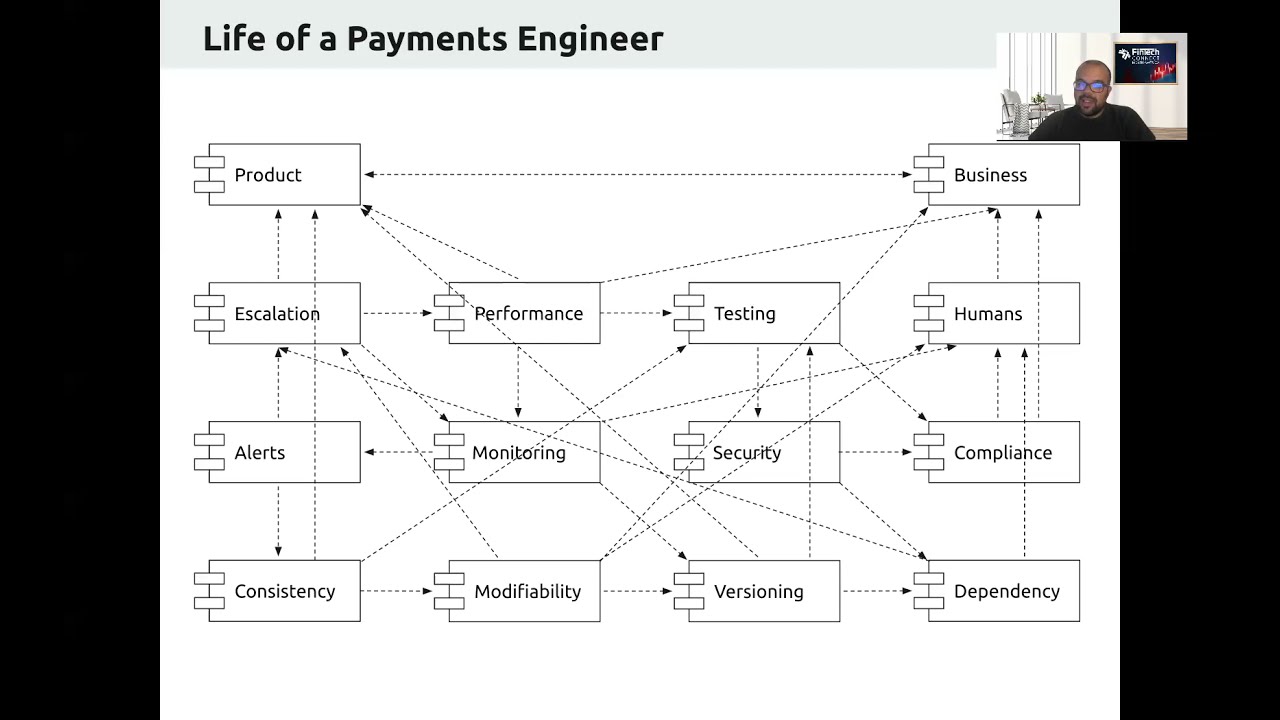
So I wanted to share a bit of Meditations with you. First of all, I want to go through how we relate to product and business teams — or other people in our companies.
[music]
We, I would say, are kind of in the middle, because we want to build something that is good for the product. So we want to enable our users to pay with more payment options, for example. But also we want to keep our business team happy by lowering our costs and reducing our charges [?], for example. So we are in the middle of those two teams.
But at the same time, from the tech perspective, we are always caring about the performance of our services. And by performance, I mean that we want a fast-working service. And that word “fast” is very relative to how many services we are calling in the background — because if our service is fast but the providers that we are using are not, we are in trouble [?].
So how do we improve our performance, and how can we make sure that we have the best performance possible? We need to test it. But again, testing is very hard, because if we mock responses from many providers in the chain of a payment, then reality in production is very different. The testing results, the load testing and performance testing that we had, are not very reliable in production. So you can say, “okay, let’s test in production” — if you dare to do it — because it’s the only place that you will be able to know exactly how you are going to perform.
Then comes the question of how do I do that securely? How do I keep the security of my tests, and of my users in general, while keeping the compliance — because we will need to test with real cards, and we’ll need to keep our users’ data secure and compliant.
I would say that the more compliance that we want to give to our service, the more difficult the performance becomes.
And that has always the influence of humans here, because humans — being developers, infrastructure, or whatever other role that we have in our team — influence in all of this all the time. We need to know exactly who is managing our data, who is managing our infrastructure, who can access everything in every point of our data. That’s a very important role.
And then to manage this performance and to manage who has access to all of this, we need to monitor very closely what’s happening in our systems all the time, and react to it as fast as possible if there is a problem. For that, it’s very hard to define alert systems — because it’s not the same to have one payment failing at 3 a.m. when the total amount of payments at that time are two, than to have all the payments failing at a big time.
Once we have an alert and we know that the alert is real, we need to know how to escalate, and to which humans, and how do we react in terms of service to that escalation.
Those alerts, for defining them, need to rely on the consistency of our data. The more consistency that we have in our result codes — how we define what is an error and what is not — the more we can do that, the better it will work.
For that, we need to be very sure that the modifiability of our services is the highest possible. For that, we need to rely on design patterns that are there for us, and the architectures that were designed for systems that rely on other systems.
Then: how do we manage versioning of our systems? If we modify our system all the time, how do we know that the previous version — and, for example, the client applications — are still working? For this, it’s not only how do we affect users and how do we see what’s happening with them, but also: how do we know that the money that we thought was in one place before, with the new version of our app, is in the same place, or where?
For that, we need to manage dependencies on old versions, and old result codes, or PSP integrations, and so on. All of this actually is very, very linked to each other, and changing all the time. You can imagine here the amount of stress that a payments engineer can have in their life, because everything is changing and everything can go wrong — without you having a hundred percent code coverage ever, because it’s impossible to test how every combination of card scheme, user, issuer, acquirer, etc. can and will act.
So I want to define some meditations here. For these I’m copying our friend Marcus Aurelius, who had the tradition of getting some notebook beside his bed every day and writing something that he thought about, he’d say. So I decided to collect a bit of my thoughts, of my learnings, in my life as a payments engineer. Of course, this is not final and this is not definitive for anyone — it’s what I think, what I collected. So I hope this will evolve, and I’m very open to you sharing your opinions and your comments and your other meditations, so we can collect a body of knowledge together.
I’m going to go fast through them because there are a lot of them. But again, I invite you to also comment after the meeting: what do you think about it, and how we collaborate with them.
So, for example:
Payments engineering doesn’t fit the usual methodologies that we use in software engineering. It’s very hard for us to define cascade — actually, it’s very old-school to define the cascades of our life cycle. But it’s also hard for us to define scrum methodologies, because when we are making a payment integration, maybe that integration has a blocker — maybe the PSP didn’t share the credentials with you, or there’s something missing in the documentation. So your whole sprint goes into waiting times.
What works for me better is Kanban — but also you should never lose the estimation. Use it as a practice to learn how and why you changed, so that you can improve your feature checklist, and how you can improve and feel it beforehand in the next.
Split the team, and be aware that you also have to take care of fraud, chargebacks, reconciliation, reporting, finance in general. Don’t make your integrations team do all the work that is around payments — because they will be overwhelmed with the work, and the knowledge that they can share will be very limited.
Also, when making an integration, don’t put only one person, because that person will become the only person that knows about that PSP, and if it goes down or has a problem, or needs a change, it will be silo knowledge that is not shared. But at the same time, don’t put your entire integration scheme on one — not good either: if the integration blocks, the entire team is blocked.
Release cycles in payments are also some problem, because the PSP — or whatever provider in the chain of a payment — can make changes at any moment, and they won’t care about how you planned your release. So if the response code that meant success for a payment goes from zero to one tomorrow, it doesn’t matter if your next version goes out next week — we need to fix it right now.
As a developer, you need to get the bigger picture of why you’re making an integration. Why do you need to make another change to this PSP? And most of all: why is it useful for our company and our users? That means that, also as a developer, you need to ask questions and make sure that the PSP integration is the right one that you need before signing a contract promising that you will deliver an integration that may break everything that you have for your users on it, or in your system.
Remember that you are also a customer, because the solution that you create is probably going to be used by people like you, or yourself. So, if you ask for 50 fields in your credit card form, and you hate filling it for testing — well, you know.
Not every PSP and every integration is a clone of the other one, but it looks like it for other teams. So be aware that you will have to explain to the product teams and to many other teams why this integration is different than the previous one, and why this one is complex in some way, if it is. This is also useful for explaining next PSPs how and what you need and when.
That feature/tech checklist that I was mentioning is, I would say, the most important thing that you kick off the conversation with the PSPs with. So: do you have a refund endpoint, and how do you call it? Which are the required parameters, etc.? That’s an obvious question to the PSPs. But there are things like: do you even have a GET endpoint to check the status of a payment? Because if you were relying on them having that and then they don’t, you will need to change your system for it — and are you prepared for that, and how much time will it take? Don’t think this is a rare example, because it happens to the main providers in the market right now. I’m not gonna name names.
Besides this checklist, diagrams, glossaries [?] and documentation on the documentation of the providers — because all of them are very creative, and they have different names for any operation, and they all call the same endpoints differently. For example: credit, void, cancel, refunds — are all possible synonyms. Or they are talking about one-step or two-step authorizations. But you need to know what is what for every PSP.
Also, your team needs to know the difference between those operations, and the difference between a scheme, brand, network, etc. — because when something fails, you need to point to who exactly, and what is failing.
For doing that, it’s very important that you keep all the data that you can, because you will be needing it at a future moment. But also — and especially if you are in Europe — be careful on what you’re storing, and if you are being compliant with PCI.
Log everything that you can, but also be aware that logs can store some sensitive data. For example, if you are trying to mask credit card numbers in the credit card field, you could be logging unintentionally credit card numbers if the user mistyped their card in the holder name, or in another field [?].
And this means: do not use, or try not to use, the back office of the PSP — because if your team or you have a certain process that modifies payments on the PSP or on the provider side, your data will be out of date. And not every PSP has webhooks or notifications to let your server know that someone changed the status of a payment.
So, about your providers: the PSPs have their own product and their own timeline. So be aware of what they actually have, and what they are going to release in the future. They have a lot of features that you may or may not use depending on how you design yours.
As soon as you start your integration, find the support that you need from them. Collect emails, phones, even home addresses if you can — because it’s very important for you to find who to talk to when things go wrong. As a developer, it’s very useful (or it was very useful for me) to find allies in the developer team of the PSPs or the providers, because we speak the same language, let’s say, and we know what to ask and how to answer those questions.
Define escalations: how, and who will you call, and when, inside your team and at the PSP.
Does it really work? It happened to me that we signed a contract with a PSP and then the PSP was actually still creating their services. So ask them in a really early stage for a demo, and a real solution, or other clients working with that PSP.
The next one I think is for life: don’t idealize how others are going to work. And this applies to services, APIs and people. You should be defensive about how you call the APIs on your PSP.
Test in production — that’s a real thing. There’s no way you can avoid it, because the only chance that you have for testing how a payment goes through all the chain is in production. Plan from the very start how you’re gonna do it.
Also, very related to testing in production: have a big red button to turn everything off if it’s failing. And this sounds like an obvious thing, but it happens sometimes that you code something that exists there forever, and you have no easy way to turn it off unless you make another release or release another version of your application.
You should also define dynamic alerts. So again, you shouldn’t cry wolf for every payment that fails — but also, you should cry very loudly, let’s say, when a payment is actually failing a lot, or a PSP is completely down.
Dashboards for dummies — and I don’t mean that the people that read dashboards are dummies, but I mean that you have to have a big yes/no answer to the question of: “is this working now?” So it doesn’t mean that you need to have how many payments are being successful, but you need to have anomaly detection on how many should be passing and how many are actually passing.
Know your timeouts in every service. The chain for a payment goes from the user using a client-side application, to your web server, to your app server, a PSP, a gateway, fraud prevention service, the network, the banks, etc. — so all of them have different timeouts. Everything can time out in chain if one of them starts delaying answers. So it’s very important that you know who it was, and: could you configure it better?
Related to this, you should log when something goes wrong — and that’s the way that you really need to make sure who to accuse when something goes wrong. And when you are going to accuse, complain with facts, let’s say — so collect information about what’s failing and when, and what were you trying to do, and what was the actual result. It’s very common that when you talk to other people or providers and you tell them, “hey, something is wrong on your side,” their first reaction will probably be: “no, it’s wrong on your side.” So how are you going to prove it’s on one side or the other?
I’m not saying that they are evil — but what I’m saying is that it’s very hard to define what’s wrong in one point when everything else is actually working.
I recommend scheduling weekly or monthly calls with the PSPs, even after — well, at any time, before the integration starts and during the integration. So you ask questions about the iterations, but also after, you need to check if they are actually getting the same statuses, seeing the same numbers as you. And you should realize if you are not, as soon as possible, to fix it.
Then, about your code:
Ask very early the most stupid questions, because they seem like stupid: what fields are required, in which formats should you send them, what if I send you a number where I should send a string? Because the sooner that you ask these questions, the sooner that you can fix future problems.
With PSPs, you should integrate as many as possible — but also: one is very bad, because you will tie your integration to that PSP, possibly using the same names as them in the API endpoints and the entities, and then the second PSP will probably break those assumptions that you made. But also, too many integrations is also bad, because you will have so many different variations of how you integrate with payments that it will become a mess to maintain. So you can find many PSPs that serve as allies, or service hubs let’s say, for other integrations, so that you can simplify how you perform payments.
This is also related to what I mean about aggregating integrations — meaning that, if you have some similar integrations, you can define a naming for them, like “alternative payment methods”, or “one-time-usage token integrations”, “vault card integrations”, etc. All of those have small differences among themselves but big ones to the others. So create categories and group code together.
Make the code speak. Show your product people and your business people what your mappings from raw response codes to your internal codes are — because there will be a lot of discussion around how we interpret the response from the PSPs. So showing the actual code can be a tool for you in those discussions.
Reduce client-side code. This is also very important for changing the versions of your applications. If, for example, the way that you capture the credit card data on the client side changes all the time, it’s very hard to maintain the versioning and the dependencies that I was mentioning before.
Designing for extension means that you will have PSPs that communicate with other PSPs and other PSPs — so how do you call that integration? Be prepared for extending and inheriting in those classes that you are creating.
Defensive programming means that even something simple — an if that is expecting something that can be true or false — can break. Because if you defined it, for example in Java, with a Boolean with uppercase B, it can also be null. So these small things are going to be very important while fixing issues in production.
Feature flags is something that helps you a lot with this, and also with production testing. Feature flags mean that you can release or roll out a new version slowly, but it also means that you can also allow payments to certain users in certain scenarios. And that’s super useful for testing.
Fake PSPs for load testing means that you can take some PSP and simulate it — like simulate timeouts, and simulate responses, and variations or anomalies in their responses. That’s very useful if you don’t want to test everything in production.
Validating your requests before sending them to the PSP is very helpful, because sometimes the response message from the PSP about how a request was malformed is not very clear. So if you yourself ensure that your request is clear, it’s much better.
Asynchronicity in your processing is very, very necessary and useful, because you don’t want a chain reaction in your payment chain. If you tell the user “I’m gonna process your payment asynchronously and let you know when it’s ready,” you can work much better with timeouts and possible problems with the PSPs. So whenever possible, use async.
Those ifs that you have for configurations — like, “if the card is Visa and the bank is this one, then do this” — could be very helpful for hot fixes in production. But be very careful also with those hardcodings, because it’s very easy to miss them when you’re checking for strange behaviors.
Give SOAP a rest — I mean that REST and microservices are a hype thing nowadays, but actually SOAP had something very useful, which was a constant signature for methods, and a very stable interface in web services. Many PSPs are still using them in the day-to-day, so don’t forget about it, and be prepared for your payments service or API to be talking with SOAP APIs and REST APIs and whatever else is coming in the future.
SDKs are not that good — and that means that many PSPs try to make our work easier by giving us SDKs (sorry, as the case [?]) hiding complexity from callers. But sometimes they are not very optimized, and they don’t use the best dependency versions, for example — and you end up in the famous dependency hell that was very common in Node.js and the JavaScript world.
About your data, this time:
Detailed errors avoid questions. If you tell clients exactly what happened, they will know how to react to it. If they didn’t have enough money on the card, maybe they change the card, instead of trying 20 more times. But be careful with what you share with them, because it’s very sensitive information in some cases, and fraudsters can use that information for their benefit.
Be careful with the differences between null, the empty-string version of null, and some dummy data that you’re sending to PSPs, because it can be problematic to find when you’re looking for bugs.
Size matters. For example, cardholder names in cards have a limit, usually 20 or 50 characters — and if you don’t clean that data, it can cause a slight amount of errors that you don’t capture in the beginning. Also, some PSPs or some cards have a minimum size in fields. It can happen that users that put one letter or an initial in the field that you call “first name” creates a lot of problem with you.
Formats in numbers, currencies, dates can be very different in your server than in your PSPs. So be very careful with how they handle it — all of them handle it differently. So you could have, for example, helper classes in your service to convert into different versions of what they need.
When a provider is telling you that something is optional, you should assume that it’s actually mandatory — because it can become and will become mandatory in the future. So if you have that data, start sending it as soon as you have it.
Billing and shipping addresses can be different. Are you asking for them in your checkouts? If not, can you send the same information in the shipping address as in the billing address — or will it be rejected by fraud? So, all of those: ask them soon in the process to avoid problems.
We talked already about the GET operations, especially for polling status of a payment in the future.
Statement descriptors — you should care a lot about them, because when users are complaining about their payment not being in the status that they wanted, you want to identify exactly which payment, when it was made, and how it looks on their card statement.
This also means that you should insert instead of updating your payments — because you want to know how that payment was evolving and changing over time, and you want to keep all the possible statuses that it had in history, and also who changed that payment from which status to the other.
JSONs. This is very controversial, because I would say that you should store exactly what you received and what you sent to and from the PSP — because there are gonna be lots of discussions of what you sent and what you didn’t. So if you can store exactly what you sent, usually in JSON, [do it]. But be very careful on what you store again — no sensitive information, and no temporary information in there.
Have IDs everywhere, because it’s very important that you can reconcile your payment in every possible database — in yours, in the finance system, maybe in your own company. Chargebacks have many different IDs, because it can be the ID of the payment in your server, in the acquirer, in the issuer; it can be a daily ID of how they settle payments. So store all of them, to make sure that you are managing the correct information.
Also, store card tokens — or card vaults [?], both versions — as a list, because you may change from one vault to the other in the future, so it’s not a one-to-one relationship.
That is all for now, but this list is growing every day, as I said. So I thank you for your attention, and for your participation.
And again — what you can learn, and you should learn from the stoics in this, is that there’s a lot that is not in your control when you’re talking about payments engineering, and there’s a lot also that you can control — especially how do you react to errors, how do you react to an unexpected response, how do you map responses, and how well are you prepared for changing that mapping all the time.
So yes, you can complain about how the industry needs standardization. You can complain to the business team that you are very happy with this PSP and you don’t want to change to this other one. And you can complain to the product team about needing more time to make this integration better. But be careful: how can you make sure that you control those topics, and how can you explain yourself when you are saying, “I want to influence this topic, but I don’t control it a hundred percent”?
Seneca lived 2,000 years ago, but I think he would have been an amazing payments programmer, because he knew exactly what to worry about and when.
Thank you all for participating again, and have a really good day, and I hope you’re staying healthy in this quarantine. Hope to also see you.